

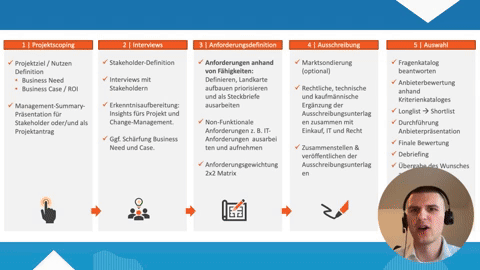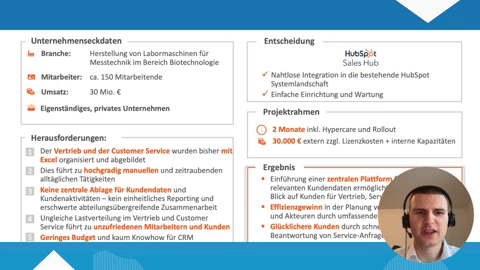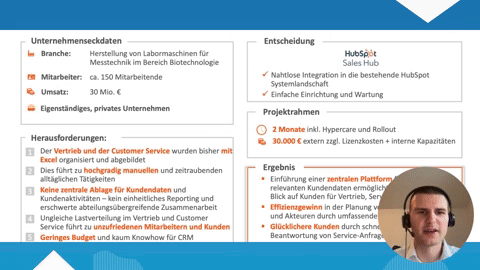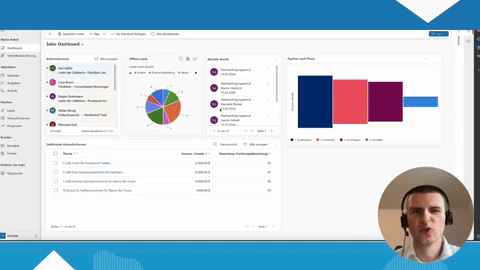
Data Mining
Inhaltsverzeichnis
- Definition: Was ist Data Mining?
- Was ist der Unterschied zu Big Data?
- Welche Methoden nutzt das Data Mining?
- Welche Anwendungsgebiete hat Data Mining?
- Wie läuft Data Mining ab?
- Welche Vorteile bietet Data Mining?
- Sonderform: Text Mining
- Salesforce und Data Mining
- Fazit: mit Data Mining Daten automatisiert auswerten
- FAQ
Definition: Was ist Data Mining?
Unter Data Mining versteht man die systematische Anwendung von Methoden und Algorithmen, um in Datensätzen Muster, Beziehungen oder Abhängigkeiten zu identifizieren. Der Prozess ist computergesteuert und dementsprechend automatisiert. Data Mining bedient sich Kenntnissen aus der Informatik, der Statistik und der Mathematik, um die Datenmengen zu analysieren. Die identifizierten Muster und Zusammenhänge können helfen, bessere Entscheidungen zu treffen.

Künstliche Intelligenz leicht gemacht – zugänglich, kosteneffizient, sofort einsetzbar.
Was ist der Unterschied zu Big Data?
Big Data ist ein Prozess zur Verarbeitung besonders großer Datenmengen. Data Mining wird auch häufig für solche großen Datenmengen eingesetzt, ist in seiner Anwendung aber nicht darauf beschränkt und kommt auch auf kleiner Datenbasis zum Einsatz.
Während Big Data die Datenmengen zur Verfügung stellt und zusätzlich eine Plattform für die Verarbeitung bietet, beschreibt Data Mining den eigentlichen Prozess zur Datenanalyse und dem verbundenen Erkenntnisgewinn.
Welche Methoden nutzt das Data Mining?
Data Mining nutzt folgende Methoden:
- Datenaufbereitung
- Assoziationsanalyse
- Clusteranalyse
- Klassifizierung
- Abweichungsanalyse
- Data Warehousing
- Regressionsanalyse
Datenaufbereitung
Zunächst identifiziert das System beschädigte oder fehlerhafte Daten und entfernt diese – wenn nötig – aus dem Datensatz. Sämtliche Daten in diesem bereinigen Datensatz werden nun in eine für die Weiterverarbeitung und Analyse geeignete Form konvertiert.
Assoziationsanalyse
In diesem Schritt sucht das System nach Beziehungen und/oder Abhängigkeiten zwischen einzelnen Objektmerkmalen oder auch verschiedenen Objekten. Damit kann zum Beispiel eine sogenannte Warenkorbanalyse durchgeführt werden. In dieser erkennen Sie, welche Produkte Ihre Kunden für gewöhnlich in Kombination mit welchen anderen Produkten erwerben.
Clusteranalyse
Hier teilt das System die Datenmenge in mehrere Cluster auf und fasst dabei Objekte mit gleichen Merkmalen in einem Cluster zusammen. Das hilft dem Nutzer, die Struktur des Datensatzes leicht zu erfassen und ermöglicht ein schnelleres Verständnis.
Klassifizierung
Einzelnen Datenobjekten werden eindeutige Klassen bzw. Zielkategorien zugeordnet. So ist das System zukünftig in der Lage, diese Zielkategorie für neue Daten vorherzusagen und sie so selbstständig einzuordnen.
Abweichungsanalyse
In der Abweichungsanalyse erkennt das System Objekte, die nicht den Abhängigkeitsregeln anderer Objekte entsprechen. So lassen sich ungewöhnliche Datensätze herausfiltern und Ausreißer oder Fehler leicht erkennen. Darauf basierend kann auch die Ursache für die Abweichung gefunden werden.
Data Warehousing
Als Data Warehousing wird eine groß angelegte Sammlung sämtlicher Geschäftsdaten bezeichnet. Diese Daten sollen bei der Entscheidungsfindung unterstützen. Die Datensammlung ist Grundlage vieler Data Mining Projekte.
Regressionsanalyse
Die Regressionsanalyse identifiziert die Beziehung zwischen mehreren abhängigen sowie unabhängigen Variablen. Sie kann als Prognosetool eingesetzt werden und so eine Reihe numerischer Werte auf Basis der vorhandenen Daten vorhersagen.
Welche Anwendungsgebiete hat Data Mining?
Beschreibungsmodelle
Für diese Modelle zur Beobachtung und Beschreibung bestimmter Situation wird beispielsweise die Clusteranalyse eingesetzt, sodass Nutzer die Datenmengen besser überblicken und schneller Erkenntnisse aus ihnen gewinnen können. Konkret können so Käuferprofile identifiziert oder Marktsegmentierungen durchgeführt werden.
Erklärungsmodelle
Erklärungsmodelle gehen einen Schritt weiter und versuchen aus den Datenbeziehungen Kausalitäten zu erklären. Zu diesen Modellen gehören z. B. Warenkorbanalysen oder die Identifikation von Erfolgsdeterminanten einer Online-Präsenz.
Prognosemodelle
Mit Hilfe von Klassifizierung und Regressionsanalyse können diese Modelle bis jetzt unbekannte Merkmale auf Basis der bereits analysieren Merkmale vorhersagen. Das kann z. B. auf Aktienkurse angewendet werden und so die Finanz- bzw. Investitionsplanung unterstützen.
Wie läuft Data Mining ab?
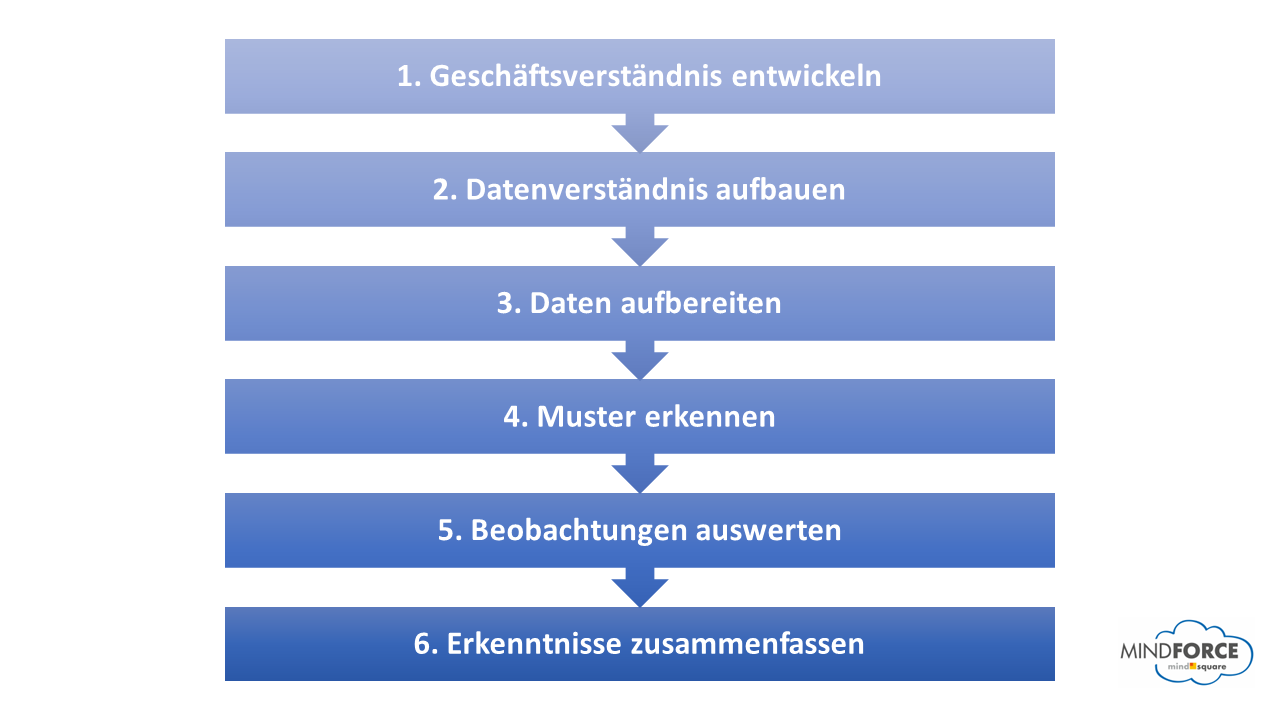
1. Geschäftsverständnis entwickeln
Als erstes sollten die Projektparameter genau geklärt werden. Dazu gehört auch ein Verständnis der aktuellen Unternehmenssituation, der wichtigsten Projektziele und der verbundenen Erfolgskriterien.
2. Datenverständnis aufbauen
Im nächsten Schritt werden diejenigen Daten definiert, die zur Problemlösung gebraucht werden. Anschließend werden diese Daten aus sämtlichen Quellen zusammengetragen, sodass sie im Folgenden gemeinsam verarbeitet werden können.
3. Daten aufbereiten
Nun kann man die gesammelten Daten in das benötigte Dateiformat konvertieren. Gleichzeitig läuft die Behebung von Datenqualitätsproblemen ab. Das bedeutet, doppelte oder beschädigte Daten werden entfernt.
4. Muster erkennen
In diesem bereinigten Datensatz werden nun Algorithmen angewandt, die Muster und Zusammenhänge identifizieren und somit die Datenanalyse ermöglichen.
5. Beobachtungen auswerten
In der Auswertung gilt es zu ermitteln, ob und wie gut die Ergebnisse eines bestimmten Modells zur Erreichung des Unternehmensziels beitragen. Es kann häufig etwas dauern, den passenden Algorithmus zu finden und so auch die richtigen Erkenntnisse aus den Daten zu ziehen.
6. Erkenntnisse zusammenfassen
Abschließend werden die Projektergebnisse zusammengefasst und dem Entscheidungsträger zur Verfügung gestellt.
Welche Vorteile bietet Data Mining?
Grundsätzlich lassen sich mit den Erkenntnissen aus dem Data Mining bessere Entscheidungen treffen, da diese nicht auf Instinkt, sondern auf objektiven Daten basieren. So kann man beispielsweise ein besseres Verständnis der eigenen Kundensegmente aufbauen. Das erleichtert die Kundenakquise, den Aufbau einer Kundenbindung sowie die Nutzung von Cross-Selling-Potenzialen.
In diesem Prozess der Datenanalyse bringt das automatisierte Data Mining eine Zeitersparnis, da die Daten nicht mehr manuell von Ihren Mitarbeitern ausgewertet werden müssen. Diese können sich stattdessen darauf konzentrieren, mit den Erkenntnissen der Analyse zu arbeiten und so Ihren gesamten Geschäftsprozess zu optimieren.

Sonderform: Text Mining
Während das gewöhnliche Data Mining auf strukturierte Daten angewendet wird, dient das Text Mining der Analyse von unstrukturierten Daten, also Textdaten. Beide haben das Ziel der Informationsgewinnung. Dementsprechend will das Text Mining Wissen aus Texten extrahieren und dem Nutzer wichtige Erkenntnisse liefern. So können die wichtigsten Aussagen aus einer Vielzahl von Texten zusammengefasst werden, sodass der Nutzer die Inhalte einer viel größeren Quellenmenge leicht überblicken kann, ohne jeden Text im Detail gelesen zu haben.
Salesforce und Data Mining
Salesforce bietet umfassende Data-Mining-Funktionen, mit denen Unternehmen Erkenntnisse aus ihren Daten gewinnen und fundierte Geschäftsentscheidungen treffen können:
- Einstein Analytics (auch: Tableau CRM): Salesforce Einstein ist eine in die Salesforce-Plattform integrierte künstliche Intelligenz. Es ermöglicht, große Datenmengen zu analysieren, Muster zu erkennen und Vorhersagen zu treffen. Nutzer können Dashboards und Apps personalisieren, um geschäftsrelevante Daten zu visualisieren und zu analysieren.
- Customer 360: Dieses Tool hilft Unternehmen, ein einheitliches Bild ihrer Kunden über verschiedene Kanäle und Interaktionspunkte hinweg zu erhalten. Data-Mining-Techniken werden eingesetzt, um das Kundenverhalten zu analysieren und personalisierte Kundenerlebnisse zu schaffen.
- Salesforce Reports und Dashboards: Mit diesen Tools können Nutzer komplexe Datenanalysen durchführen, Trends erkennen und Berichte in Echtzeit erstellen. Diese Funktionen unterstützen das Data Mining, indem sie tiefe Einblicke in die auf der Salesforce-Plattform gesammelten Daten ermöglichen.
Fazit: mit Data Mining Daten automatisiert auswerten
Die riesigen Datenmengen, die Unternehmen heutzutage erheben, können Unternehmen nicht mehr manuell verarbeiten und analysieren. Mit Data Mining automatisieren Sie diesen Prozess und haben Zugriff auf Beobachtungen und Erkenntnisse, die Sie ohne die Algorithmen gar nicht erzielen könnten. So können Sie faktenbasierte und damit bessere Entscheidungen treffen. Gleichzeitig sparen Sie wertvolle Zeit.
Kostenlose Websession
Wenn Sie IT-Unterstützung bei der Optimierung Ihrer Vertriebsprozesse benötigen, dann kontaktieren Sie uns gerne. Wir haben das entsprechende Prozessknowhow und die Erfahrung in unterschiedlichsten Branchen. In einer kostenlosen Websession können wir über Ihre Herausforderungen und Anforderungen sprechen.
FAQ
Was ist Data Mining?
Data Mining ist ein computergestützter Prozess, der Methoden und Algorithmen verwendet, um Muster und Zusammenhänge in großen Datensätzen zu identifizieren. Diese Erkenntnisse helfen, bessere Entscheidungen zu treffen.
Wie unterscheidet sich Data Mining von Big Data?
Big Data bezieht sich auf die Verarbeitung und Verwaltung großer Datenmengen, während Data Mining den eigentlichen Analyseprozess dieser Daten beschreibt, um Erkenntnisse zu gewinnen. Data Mining kann sowohl auf großen als auch auf kleinen Datenmengen angewendet werden.
Wie läuft der Data-Mining-Prozess ab?
Der Data-Mining-Prozess umfasst die folgenden Schritte:
- Geschäftsverständnis entwickeln
- Datenverständnis aufbauen
- Daten aufbereiten
- Muster erkennen
- Beobachtungen auswerten
- Erkenntnisse zusammenfassen
Welche Vorteile bietet Data Mining?
Data Mining ermöglicht bessere Entscheidungen durch objektive Datenanalyse, spart Zeit durch Automatisierung und hilft, Kundenprofile zu verstehen, die Kundenbindung zu verbessern und Cross-Selling-Potenziale zu nutzen.
Wer kann mir beim Thema Data Mining helfen?
Wenn Sie Unterstützung zum Thema Data Mining benötigen, stehen Ihnen die Experten von Mindforce, dem auf dieses Thema spezialisierten Team der mindsquare AG, zur Verfügung. Unsere Berater helfen Ihnen, Ihre Fragen zu beantworten, das passende Tool für Ihr Unternehmen zu finden und es optimal einzusetzen. Vereinbaren Sie gern ein unverbindliches Beratungsgespräch, um Ihre spezifischen Anforderungen zu besprechen.







